Toutes les Meilleures Stratégies RAG dans un Seul MCP pour Assistants de Codage IA
Ne souhaitez-vous pas que votre assistant de codage IA puisse vraiment comprendre votre projet et sa documentation ? L’un des plus grands problèmes que nous rencontrons avec les codeurs IA en général est qu’ils hallucinent constamment lorsqu’ils intègrent des bibliothèques et des outils dans nos projets, qu’il s’agisse de Superbase, MCP, Pantic AI ou n’importe quelle autre technologie.
Une Solution Complète pour la Documentation IA
Je développe actuellement une solution majeure à ce problème. J’en ai déjà parlé sur ma chaîne, mais il s’agit de mon serveur MCP « crawl for AAI rag ». Récemment, j’ai ajouté plusieurs nouvelles stratégies RAG pour rendre ce serveur encore plus puissant, fournissant une documentation à jour à vos codeurs IA. De plus, j’ai des projets encore plus ambitieux pour ce serveur que je souhaite partager avec vous maintenant.
Mon objectif est de transformer ce serveur MCP en la prochaine évolution d’Archon. Actuellement, nous disposons de nombreux outils déconnectés pour faciliter notre codage IA :
- Les tâches boomerang dans Rue Code qui nous offrent différents agents pour gérer diverses parties du développement
- Context 7 pour fournir une documentation à jour à nos codeurs IA
- Cloud Task Manager pour transformer notre codeur IA en gestionnaire de projet
Ce sont tous d’excellents outils, ne vous méprenez pas. Mais ce que je veux construire avec ce serveur MCP, bien que ce soit un projet ambitieux, c’est combiner toutes ces fonctionnalités pour créer un serveur MCP principal qui répondra à tous nos besoins en matière de codage IA. Cela inclut une solide base de connaissances avec RAG, la possibilité d’avoir différents agents gérant différentes parties de notre projet, et nous aidant à planifier et gérer nos tâches.
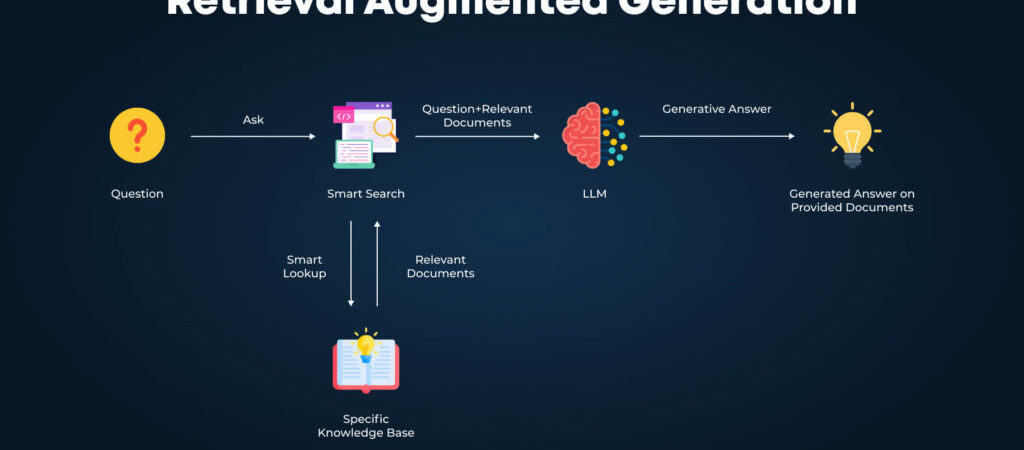
J’ai de grandes ambitions pour ce projet, et je commence par l’élément fondamental : une base de connaissances RAG. C’est pourquoi j’ai implémenté des stratégies supplémentaires que je vais vous présenter maintenant.
Installation et Configuration du Serveur MCP
Comme d’habitude, vous trouverez un lien vers ce serveur MCP dans la description. Il est complètement gratuit, open source et très facile à configurer. Le fichier README contient des instructions détaillées sur la configuration, y compris comment activer et désactiver les différentes stratégies RAG que je vais aborder.
Une fois la configuration terminée, vous pourrez connecter le serveur à votre assistant de codage IA, ainsi qu’à d’autres agents IA et à NADN. La configuration suit un processus typique pour les serveurs MCP.
Ajout de Documentation à votre Base de Connaissances
Une fois configuré, nous pouvons commencer à ajouter de la documentation dans notre base de connaissances privée, avec Superbase connecté (également expliqué dans les instructions).
Pour cette démonstration, j’utiliserai la documentation du SDK IA de Vercel. Il s’agit d’une bibliothèque front-end qui aide à créer des applications autour de vos agents IA. Ils ont une page LLM.ext qui combine toute leur documentation en format markdown, spécifiquement conçue pour être ingérée par les LLM via des outils comme notre serveur RAG MCP.
Types de Sites Web Supportés
Notre serveur MCP prend en charge différents types de sites web à explorer :
- Les textes LLM comme celui-ci (nombreuses bibliothèques proposent ce format pour leur documentation)
- La navigation récursive à partir d’une page de base
- Les sitemaps (listes de toutes les pages individuelles)
Commençons avec le fichier llms.ext, qui est le moyen le plus simple d’obtenir des connaissances pour nos assistants de codage IA.
Démonstration du Processus de Crawling
Je peux copier ce lien et dans mon interface Windsurf, utiliser la commande « crawl » puis coller le lien llms.ext. Comme mon serveur MCP est connecté, il peut maintenant utiliser ces outils pour explorer une seule page.
Dans mon terminal, tout fonctionne actuellement avec OpenAI pour les embeddings et le LLM (je prévois de prendre en charge d’autres LLM à l’avenir). Le système extrait tout le contenu et l’insère dans notre base de connaissances Superbase, y compris les exemples de code liés au RAG agentique, que nous verrons plus tard.
Windsurf m’informe que le crawling a réussi. Si je retourne dans ma base de données et que j’actualise mes sources, nous voyons maintenant AISDK.dev comme source unique. Dans cette base de connaissances, je peux consulter la table des pages explorées et voir tous les différents fragments qui ont été insérés.
J’ai déjà mis en place une stratégie de chunking robuste en arrière-plan, que je continue d’améliorer. Nous avons également nos exemples de code, une fonctionnalité récemment ajoutée qui a considérablement amélioré les résultats. En plus d’explorer toute la documentation et de la placer dans la table des pages explorées, nous pouvons utiliser un RAG agentique pour construire une seconde base de données vectorielle contenant tous les exemples de code. Cela permet à notre agent de rechercher spécifiquement des exemples en plus de la documentation, l’aidant à comprendre comment utiliser les exemples des docs pour construire quelque chose de similaire dans notre propre projet.
Utilisation Pratique du Serveur RAG
Maintenant que ma base de connaissances pour le SDK IA de Vercel est configurée, je peux poser une question comme : « Utilise la documentation du SDK IA de Vercel pour m’expliquer comment diffuser le texte d’un modèle OpenAI en streaming ». C’est un exemple simple, mais vous pourriez également l’utiliser dans votre processus de codage réel.
Le système effectue plusieurs recherches et affine ses résultats au fil du temps. Après quelques instants, nous obtenons une réponse qui semble très correcte : nous importons OpenAI du SDK IA, nous utilisons la fonction stream_text, puis nous obtenons le résultat avec le texte à la fin.
J’ai également un exemple plus complexe où j’ai pris l’un des modèles du SDK IA de Vercel et utilisé ma base de connaissances pour créer un site web élégant intégré avec Cloud 4 comme interface de chat, avec un outil pour obtenir des informations météorologiques. Vous pouvez voir que j’utilise le serveur MCP pour explorer les docs tout en créant du code, en plus d’analyser mes pages et d’apporter des modifications à mon code.
Le front-end créé est vraiment propre. Je suis parti de la démo « Get started with Claude 4 » du SDK IA, puis j’ai apporté des modifications pour l’améliorer. Je peux poser une question comme « Quel temps fait-il à Minneapolis, Minnesota ? » et l’application utilise l’outil météo pour afficher un joli résultat avec les informations obtenues, diffusées en streaming vers le front-end.
Stratégies RAG Avancées Implémentées
J’ai récemment rendu ce serveur MCP encore plus puissant en implémentant différentes stratégies pour RAG :
- Embeddings contextuels
- RAG hybride
- RAG agentique
- Reranking
Si vous souhaitez approfondir ces stratégies RAG, j’ai réalisé quelques ateliers dans ma communauté Dynamis AI Mastery. Consultez dynamis.ai si vous voulez explorer ces sujets plus en profondeur avec moi. J’y développe également un cours complet sur la création d’agents IA, avec des événements quotidiens et une grande communauté de personnes maîtrisant l’IA ensemble.
1. Embeddings Contextuels
Cette stratégie RAG a été introduite par l’équipe d’Anthropic dans leur article sur la récupération contextuelle. Au lieu d’intégrer simplement les fragments bruts de votre documentation, vous prenez chaque fragment et exécutez un prompt pour chacun d’eux.
Ce prompt préface votre fragment avec un contexte supplémentaire qui indique au LLM comment ce fragment s’intègre dans le reste du document. Voici à quoi ressemble ce prompt : vous fournissez le document entier, puis vous indiquez « voici un fragment que nous voulons situer dans l’ensemble du document ». Vous ajoutez un contexte supplémentaire pour que, lorsque le LLM récupère ce fragment, il dispose de ces informations additionnelles.
Vous pouvez utiliser la mise en cache des prompts pour que ce ne soit pas trop coûteux, même si vous devez inclure le document entier. Heureusement, nos pages de documentation ne sont généralement pas très longues.
Dans le code source, j’ai une fonction pour générer des embeddings contextuels, utilisant exactement le même prompt que dans l’article d’Anthropic, appelant OpenAI pour obtenir ce contexte supplémentaire. Notre fragment sera alors ce contexte supplémentaire préfixé, avec un triple tiret séparant le contexte du fragment lui-même.
Dans notre base de données, si je clique sur le contenu de n’importe lequel de ces fragments, nous avons ce séparateur à triple tiret où nous avons le contenu réel du fragment, mais aussi ce texte préfixé qui donne plus d’informations sur l’utilité de ce fragment. C’est particulièrement utile pour les fragments situés au milieu d’un document ou d’une page, car cela donne une meilleure idée de ce qui précède et suit cette information spécifique.
2. Recherche Hybride
La recherche hybride consiste à donner à votre agent IA la capacité d’effectuer une recherche par mots-clés en plus du RAG classique. Le RAG lui-même est une recherche sémantique, pas une correspondance exacte de mots-clés.
Parfois, cela signifie que si vous recherchez « OpenAI », les fragments renvoyés par RAG ne contiennent pas nécessairement le mot « OpenAI », alors que vous souhaitez probablement extraire uniquement les fragments qui le contiennent. La recherche par mots-clés permet d’obtenir spécifiquement ces informations de votre base de connaissances.
Dans le code, si la recherche hybride est activée (via les variables d’environnement), nous effectuons une requête pour une recherche par mots-clés insensible à la casse dans Superbase, en extrayant de nos exemples de code ou de la table des pages explorées. Nous avons des outils pour les deux, et nous vérifions si le contenu ou le résumé contient le mot-clé recherché. Nous utilisons le LLM pour déterminer certains mots-clés à extraire, puis nous combinons cela avec le RAG classique pour avoir les deux ensembles de fragments renvoyés à notre LLM.
Je peux vous montrer à quoi cela ressemble dans N8N, où j’ai construit un agent IA simple connecté à mon serveur MCP. Tout comme je l’ai connecté dans Windsurf, je le fais ici dans N8N avec mon URL SSC et le serveur MCP fonctionnant dans un terminal.
Je peux démarrer une nouvelle conversation et demander « Utilise la documentation pour me dire ce qu’est le SDK IA de Vercel ». Nous appelons l’outil « perform_rag_query » de notre serveur MCP avec la requête sur le SDK IA de Vercel, sans filtrer sur une source particulière car c’est une question très basique. Ce que nous obtenons est une combinaison des fragments issus de la recherche par mots-clés et de notre recherche sémantique (RAG classique). Il y a beaucoup d’informations car nous avons obtenu de nombreux fragments, mais ce n’est pas trop pour un LLM. Notre réponse indique que le SDK est développé par l’équipe Vercel pour créer des applications et fonctionnalités IA évolutives.
3. RAG Agentique
J’ai déjà beaucoup parlé du RAG agentique sur ma chaîne. Il s’agit de donner à votre agent IA la capacité d’explorer votre base de connaissances de différentes manières. Un modèle très courant consiste à avoir plusieurs bases de données vectorielles servant des objectifs différents, votre agent disposant d’outils pour accéder à chacune d’elles.
C’est exactement ce que nous faisons avec la table des exemples de code. Il s’agit d’une table entièrement séparée pour RAG, presque comme une base de données vectorielle distincte, où nous stockons spécifiquement tous les exemples de code liés aux bibliothèques que nous avons explorées. Nous avons les pages explorées qui contiennent toute la documentation, puis nous nous concentrons spécifiquement sur les exemples.
Je trouve les exemples extrêmement puissants. Les fournir aux assistants de codage IA les aide énormément. Avoir une section dédiée et la possibilité de les rechercher spécifiquement m’a donné d’excellents résultats.
Comme je l’ai mentionné plus tôt, nous avons un outil spécifique pour effectuer une requête RAG, pas dans les exemples de code, mais dans la table des pages explorées. C’est celui que nous avons vu être utilisé dans N8N. Mais j’ai un autre outil très similaire, cette fois pour rechercher dans la table des exemples de code. Les deux utilisent RAG, mais ce sont des bases de connaissances différentes que l’agent peut choisir en fonction de la question de l’utilisateur ou de ce qu’il essaie de coder. C’est pourquoi c’est un RAG agentique : il y a plus de raisonnement en jeu, différentes façons pour l’agent d’explorer la base de connaissances.
Pour une démonstration simple dans N8N, je vais être très explicite et demander de rechercher dans les exemples de code du SDK IA pour en trouver un utilisant la sortie en streaming d’OpenAI. Nous utilisons la fonction « search_code_examples » avec « streaming output with OpenAI » comme requête. Ce que nous récupérons ressemble beaucoup aux chunks précédents, mais ils proviennent maintenant de l’outil d’exemples de code plutôt que de l’outil « perform_rag_query ».
Dans la sortie, nous avons un exemple avec une requête POST, l’envoi de la sortie à OpenAI, puis le retour d’une réponse d’assistant. Je ne suis pas entièrement sûr que ce soit correct, mais l’important est que nous obtenons ces exemples. Nous avons cet exemple directement du SDK IA et, d’après le code que j’ai vu, nous importons « assistant_response » d’OpenAI. C’est exactement ce que je voulais : il a trouvé un exemple et me l’a présenté.
4. Reranking
Le reranking est une stratégie puissante que je n’ai pas encore abordée sur ma chaîne. Son rôle est de prendre les fragments renvoyés par notre base de données vectorielle et de les ordonner selon leur pertinence réelle pour la question ou le code que nous essayons de développer.
Il utilise un modèle d’IA distinct, appelé cross-encoder, pour analyser la requête et les fragments obtenus, puis les ordonner en fonction de la pertinence évaluée.
Dans le code, si nous utilisons le reranking (déterminé par nos variables d’environnement), nous appelons la fonction pour réordonner les résultats. Nous utilisons un modèle cross-encoder qui s’exécute localement sur votre ordinateur, téléchargé depuis HuggingFace. C’est un modèle open source que nous utilisons pour notre reranking, puis nous renvoyons les résultats triés en fonction du score.
Nous obtenons les scores en appelant « model.predict » sur toutes les paires que nous créons : paires de la requête de l’utilisateur (ou de l’assistant IA) et de chaque fragment. Puis nous les notons et les trions.
Dans N8N, nous pouvons voir à quoi ressemble cette sortie. L’élément supérieur du fragment que nous avons renvoyé des exemples de code a le score le plus élevé. Si je fais défiler jusqu’à l’endroit où nous voyons le score de reranking, nous constatons qu’il est de 3. Et si nous descendons jusqu’au dernier fragment, le score est de -10,4. Cette valeur ne signifie pas grand-chose pour nous, mais essentiellement, plus elle est petite (comme ce nombre très négatif), moins elle est pertinente. C’est pourquoi elle se trouve en bas de la liste. Et celui avec un score de 3 est le plus pertinent.
Comme nous l’avons vu en comparant avec la sortie, c’est effectivement l’exemple qu’il a décidé d’utiliser et de partager avec nous pour notre question sur la diffusion en streaming avec OpenAI.
Le reranking est un moyen puissant de renvoyer de nombreux fragments depuis RAG (par exemple 50 fragments différents), puis de n’en renvoyer que les 10 plus pertinents. C’est une façon de travailler avec plus de fragments sans avoir à en introduire davantage dans votre LLM, ce qui risquerait de le submerger et de rendre votre prompt beaucoup trop long.
Plans Futurs pour le Serveur MCP RAG
Cela m’amène à mes projets futurs pour ce serveur RAG MCP. Je souhaite implémenter encore plus de stratégies, comme le RAG multi-requêtes et l’expansion de requêtes, voire construire un RAG agentique avec des graphes de connaissances utilisant quelque chose comme Graffiti ou Light RAG.
Il existe de nombreuses stratégies différentes que je peux développer pour faire de ce serveur le meilleur serveur MCP RAG possible pour les assistants de codage IA, et j’expérimente beaucoup de choses en coulisses actuellement.
Je prends mon temps avec ce projet, c’est pourquoi nous n’avons pas vu beaucoup d’activité avec Archon jusqu’à présent. D’ici à ce que j’intègre ce serveur dans Archon et que je réoriente ma vision d’Archon pour en faire l’épine dorsale de connaissances des assistants de codage IA, je veux m’assurer d’avoir les stratégies RAG optimales.
Je continue également à développer Archon pour vous aider à gérer les tâches de vos projets et à configurer des agents pour gérer différentes parties de votre projet. J’ai tellement d’idées pour ce projet, tellement de raisons de m’enthousiasmer, et je maintiendrai ce projet open source. Je continuerai à le développer en public pour que vous puissiez suivre mon évolution et même m’aider à le construire si vous le souhaitez.
J’ai déjà quelqu’un qui m’aide à refondre l’interface d’Archon pour que nous puissions configurer l’exploration automatique afin de maintenir notre documentation à jour, gérer notre serveur MCP depuis l’interface utilisateur, et transformer Archon en une application complète que nous pourrons connecter à nos assistants de codage IA et agents IA. Il sera suffisamment générique pour devenir un RAG pour tout ce que vous voulez.
J’ai vraiment pour vision qu’Archon alimente la majorité des agents et assistants de codage IA que les gens utilisent. Je pense qu’il a ce qu’il faut pour y parvenir, et j’ai une vision claire pour l’amener jusque-là.
Conclusion et Invitation à Participer
Voilà tout ce que j’ai actuellement pour ce serveur MCP « crawl for AI rag » et mes projets pour en faire la prochaine évolution d’Archon. Je tiens à souligner à nouveau qu’il s’agit et continuera d’être un projet entièrement open source.
Vous pouvez vous impliquer de nombreuses façons : en m’aidant à apporter des modifications via des PR sur GitHub, en me faisant des suggestions dans les commentaires ou dans le dépôt GitHub. Toute forme de participation serait grandement appréciée, car c’est un projet ambitieux et j’ai besoin de votre aide.
Si vous avez apprécié ce contenu et que vous attendez avec impatience d’autres informations sur ce serveur MCP ou les agents IA en général, n’hésitez pas à laisser un like et à vous abonner.